
In the rapidly evolving landscape of artificial intelligence, Large Language Models (LLMs) have emerged as powerful tools for various applications. However, deploying LLM agents in production environments presents unique challenges. This comprehensive guide explores the path to production for LLM agents, offering insights into architectural approaches and best practices to help you navigate this complex terrain.
Introduction
The rise of LLMs has revolutionized the field of artificial intelligence, enabling sophisticated natural language processing and generation capabilities. However, transitioning LLM agents from experimental prototypes to robust, production-ready systems requires careful planning and implementation. In this article, we'll delve into the intricacies of deploying LLM agents, focusing on decoupling reasoning and planning from action and observations.
1. Understanding LLM Agents: Planning, Reasoning, Actions, and Observations
Before we dive into the production aspects, it's crucial to understand the components of LLM agents. These systems typically involve four key elements:
- Planning: Determining the steps needed to achieve a goal
- Reasoning: Analyzing information and making logical inferences
- Actions: Executing specific tasks based on the plan and reasoning
- Observations: Gathering and processing information from the environment
Traditional approaches often blend these components, leading to inefficiencies and challenges in production environments. According to recent studies, popular LLM-based agent patterns like ReAct tend to generate redundant tokens and lack control over intermediate actions and end results.
2. The Challenges of Deploying LLM Agents in Production
Deploying LLM agents in production environments presents several challenges:
- Inefficient token generation: Blended reasoning and action execution can lead to excessive token generation, increasing costs and reducing performance.
- Difficulty in monitoring and debugging: Integrated systems are often challenging to monitor and debug at scale.
- Hallucinations and inconsistencies: LLMs can sometimes produce incorrect or inconsistent outputs, which is problematic in production scenarios.
- Scalability issues: As the complexity of tasks increases, scaling LLM agents becomes increasingly difficult.
To address these challenges, a new approach is needed that separates the different components of LLM agents.
3. The ReWOO Approach: Decoupling Components for Better Performance
Recent research from Microsoft introduced the ReWOO (Reasoning, Working, and Observation) approach, which decouples reasoning, planning, and action-taking into separate components. This method has shown promising results, including:
- 65% reduction in token usage (resulting in lower API costs)
- 4-5% improvement in accuracy of generated answers
- Better handling of tool usage failures
Let's explore how the ReWOO approach works using a sequence diagram:
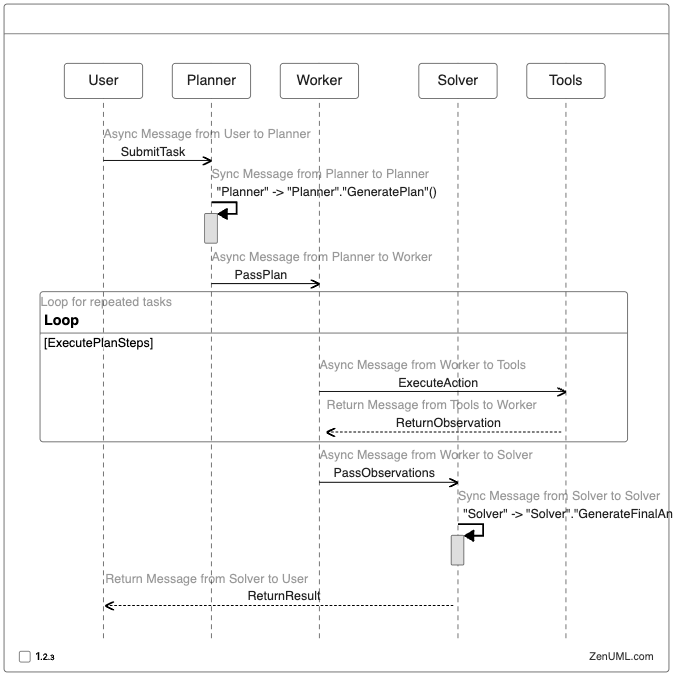
This sequence diagram illustrates the flow of information and actions in the ReWOO approach, highlighting the separation of concerns between different components. Let's break down each component:
3.1 Planner
The Planner is responsible for generating possible strategies for executing tools and other steps to solve the problem. It takes the user's task as input and produces a structured plan for the Worker to execute.
3.2 Worker
The Worker executes the tasks outlined in the plan. It interacts with various tools and systems to carry out the necessary actions and collect observations.
3.3 Solver
The Solver generates the final answer based on the results from the Worker and the original plan. It synthesizes the observations and produces a coherent response to the user's task.
By implementing these components separately, we gain better control over the LLM agent's behavior and can more easily monitor and debug each step of the process.
4. Combining ReWOO with RAG Architectures
To further enhance the capabilities of LLM agents, we can combine the ReWOO approach with Retrieval-Augmented Generation (RAG) architectures. This combination allows us to leverage external knowledge sources while maintaining the benefits of decoupled components.
Here's a high-level sequence diagram illustrating how ReWOO and RAG can be combined:
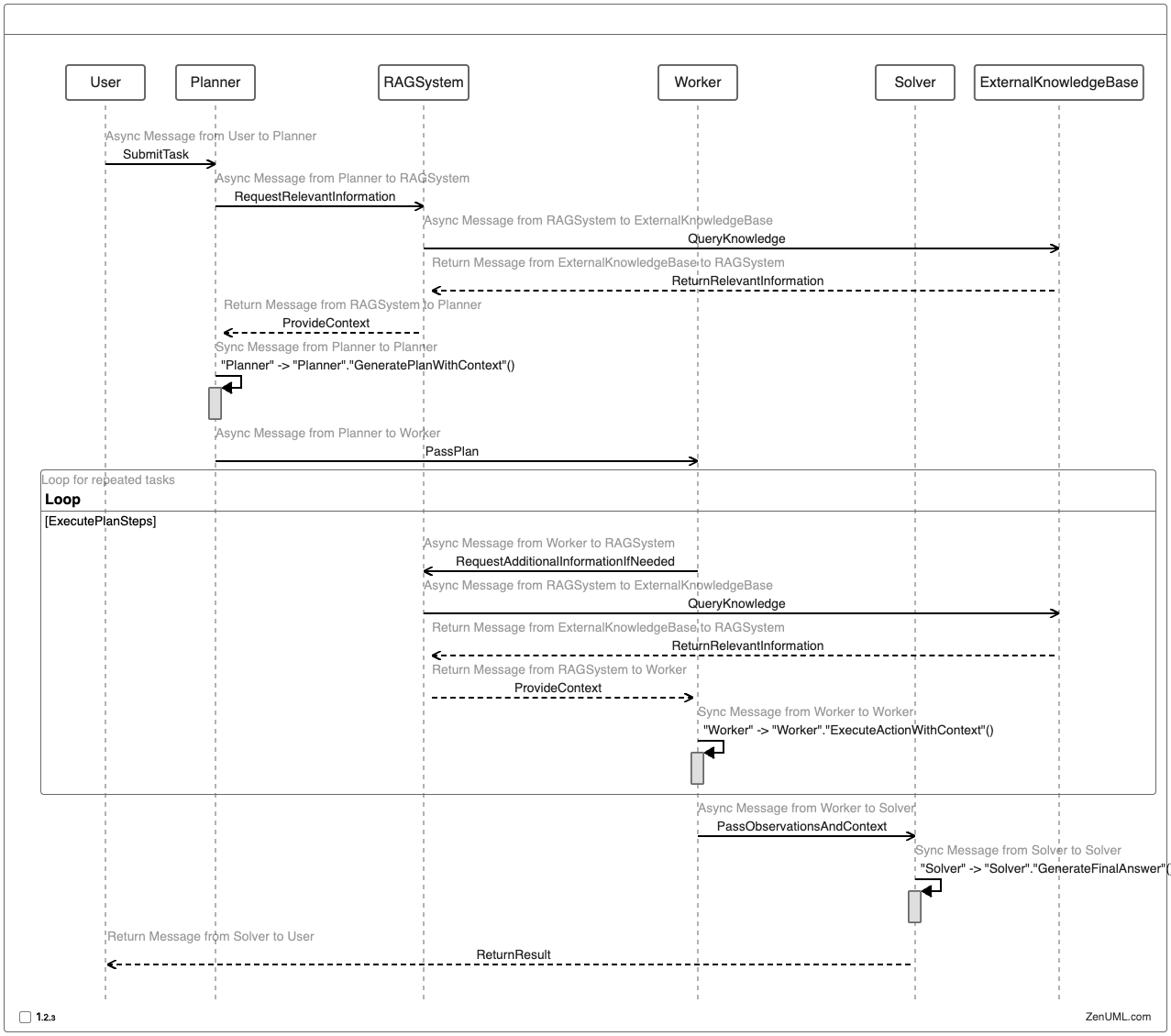
This approach allows the LLM agent to access external knowledge at various stages of the process, improving the quality and relevance of its outputs. The RAG system acts as an intermediary between the LLM components and the external knowledge base, providing contextual information as needed.
5. Microservice-Oriented Implementation
To deploy LLM agents in a production environment, a microservice-oriented architecture can provide scalability, flexibility, and ease of maintenance. Here's a sequence diagram illustrating how the ReWOO approach can be implemented using microservices:
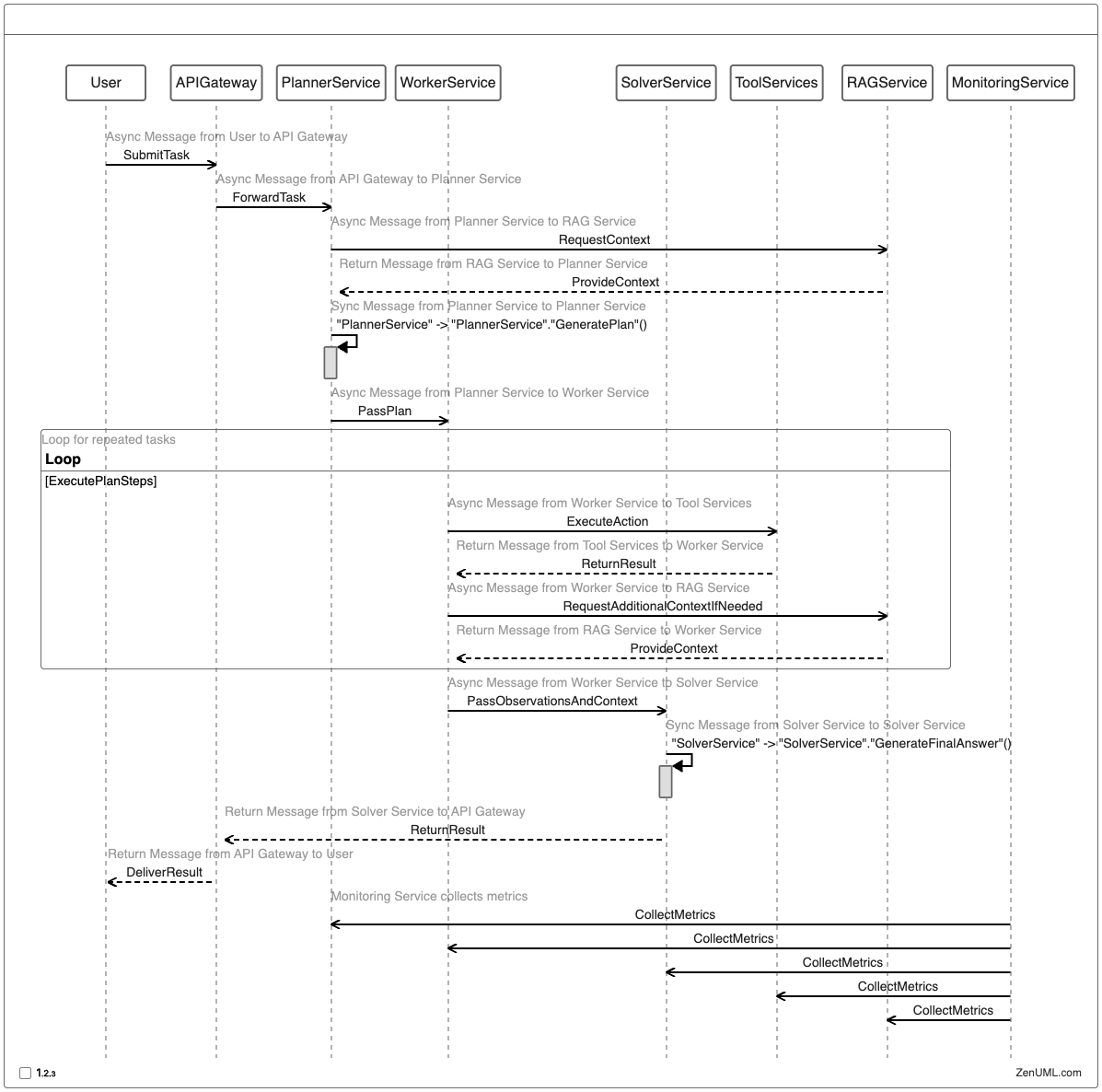
This microservice architecture provides several benefits:
- Scalability: Each component can be scaled independently based on demand.
- Flexibility: Services can be updated or replaced without affecting the entire system.
- Resilience: Failures in one service don't necessarily compromise the entire system.
- Monitoring: The Monitoring Service can collect metrics from each component for comprehensive system oversight.
6. Best Practices for Deploying LLM Agents in Production
As you prepare to deploy LLM agents in production environments, consider the following best practices:
- Modular architecture: Adopt a modular approach like ReWOO to separate concerns and improve maintainability.
- Robust monitoring: Implement comprehensive monitoring for each component to quickly identify and address issues.
- Fallback mechanisms: Design fallback strategies for scenarios where LLM outputs are unreliable or inconsistent.
- Continuous evaluation: Regularly evaluate the performance of your LLM agents and fine-tune as necessary.
- Ethical considerations: Ensure your LLM agents adhere to ethical guidelines and respect user privacy.
7. Future Trends in LLM Agent Deployment
As the field of artificial intelligence continues to evolve, we can expect several trends to shape the future of LLM agent deployment:
- Specialized LLMs: The development of domain-specific LLMs tailored for particular tasks or industries.
- Improved planning capabilities: Advancements in LLM planning abilities, potentially through the use of techniques like PDDL (Planning Domain Definition Language).
- Enhanced integration: Better integration between LLM agents and existing enterprise systems and workflows.
- Explainable AI: Increased focus on making LLM agent decisions more transparent and explainable.
To illustrate the potential future of LLM agent architectures, consider this speculative sequence diagram:
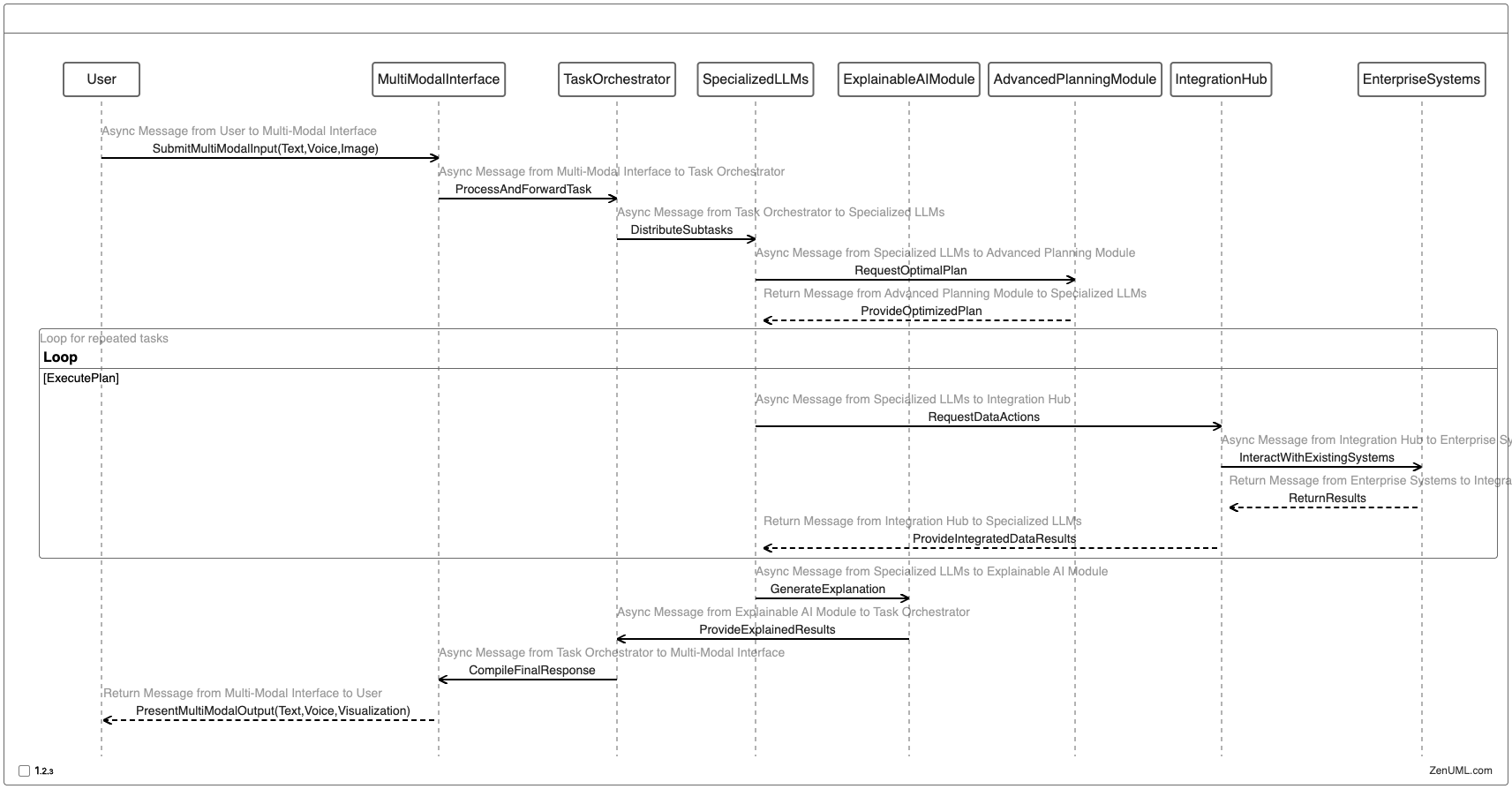
This futuristic architecture incorporates advanced features like multi-modal interfaces, specialized LLMs, explainable AI, and seamless integration with enterprise systems.
Conclusion
The path to production for LLM agents is complex but promising. By adopting approaches like ReWOO, combining them with RAG architectures, and implementing them in a microservice-oriented framework, we can create more efficient, reliable, and powerful AI systems. As you embark on your journey to deploy LLM agents in production, remember to focus on modularity, monitoring, and continuous improvement.
We'd love to hear about your experiences with deploying LLM agents in production environments. Have you encountered any unique challenges or discovered innovative architectural solutions? Share your thoughts in the comments below and let's continue this important conversation!
Try ZenUML now!
Zenuml detailed feature roadmap available here.